
تکامل مدلهای رتبهبندی اعتباری در صنعت بانکداری از روشهای قضاوتی ذهنی بهسمت تکنیکهای پیچیده یادگیری ماشینی و هوش مصنوعی قابل توضیح (XAI) پیشرفت کرده است. در اوایل قرن بیستم، این مدلها عمدتا بر اساس قضاوت شخصی مسئولان اعتباری بودند که اغلب به ناسازگاریها و سوگیریها منجر میشد. در دهههای بعد، معرفی روشهای آماری مانند تحلیل ممیزی و رگرسیون و سپس استفاده از شبکههای عصبی و ماشینهای بردار پشتیبان، تحولات مهمی در دقت و شفافیت ارزیابیهای ریسک اعتباری ایجاد کرد. در دهه ۲۰۱۰، با ورود یادگیری عمیق و روشهای ترکیبی، امکان تحلیل دقیقتر دادههای غیرساختاریافته فراهم شد. ظهور XAI در دهه ۲۰۲۰ بر شفافیت و عدالت در ارزیابیهای اعتباری تاکید میکند و استفاده از مدلهای ترکیبی و دادههای جایگزین، آیندهای هوشمندتر و منصفانهتر برای ارزیابی ریسک را نوید میدهد.
این مقاله نگاهی جامع به تحول تاریخی و پیشرفت مدلهای رتبهبندی اعتباری در بانکداری میاندازد.
سیر تاریخی توسعه مدلهای رتبهبندی اعتباری
اوایل قرن بیستم: مدلهای قضاوتی و ذهنی
در اوایل قرن بیستم، رتبهبندی اعتباری در صنعت بانکداری بهشدت بر مدلهای قضاوتی متکی بود که به قضاوت شخصی و تجربه مسئولین وام وابسته بودند. این مدلها از ارزیابیهای ذهنی بر اساس «پنج c اعتباری» استفاده میکردند: شخصیت، ظرفیت، سرمایه، وثیقه و شرایط. (کراهنن و وبر، ۲۰۰۱). با این حال، این روش فاقد ثبات و انصاف بود، زیرا مسئولین وام میتوانستند متقاضیان مشابه را بهطور متفاوتی ارزیابی کنند که منجر به رتبهبندیهای اعتباری غیر قابل اعتماد میشد. افزایش حجم درخواستهای اعتباری، محدودیتهای این مدلهای قضاوتی را آشکار کرد و نیاز به رویکردی عینیتر و سیستماتیکتر برای ارزیابی ریسک اعتباری را برجسته ساخت. (ساندرز و آلن، ۲۰۰۲؛ آلتمن، ۱۹۶۸)
دهه ۱۹۵۰: مدلهای امتیازدهی اعتباری
دهه ۱۹۵۰ با معرفی امتیازدهی اعتباری، نقطه عطفی بهسمت مدلهای کمّی بود. این مدلها از تکنیکهای آماری مانند تحلیل ممیزی چندگانه (MDA) برای طبقهبندی وامگیرندگان و بر اساس نسبتهای مالی استفاده میکردند. (بیور، ۱۹۶۶) امتیازدهی اعتباری با تکیه بر دادههای قابل سنجش مانند درآمد و سطوح بدهی، ثبات بیشتری به فرایند ارزیابی اعتباری آورد و تاثیر تعصبات شخصی را کاهش داد. (جونز، ۱۹۸۷)
کارهای پیشگامانه دوراند (۱۹۴۱) و فیشر (۱۹۳۶) به توسعه مدلهای آماری پیچیدهتر کمک کرد، در حالی که کاپلان و اورویتز (۱۹۷۹) مدلهای رتبهبندی اوراق قرضه را پیشرفت دادند. این تلاشها رویکردی مبتنیبر داده را برای ارزیابی ریسک اعتباری ایجاد کرد.
دهه ۱۹۶۰: رگرسیون خطی و آغاز مدلسازی کمی
در دهه ۱۹۶۰، رگرسیون خطی بهعنوان یکی از نخستین ابزارهای کمی برای تحلیل ریسک اعتباری معرفی شد. این روش امکان بررسی روابط میان نسبتهای مالی و احتمال نکول را فراهم میکرد و دیدگاه عددی و تحلیلیتری نسبت به ارزیابی ریسک به وجود آورد. اگرچه رگرسیون خطی بهدلیل سادگی و قابلیت تفسیر، توجه بسیاری را جلب کرد، اما محدودیتهایی نیز داشت، از جمله فرض خطیبودن روابط بین متغیرها، حساسیت به دادههای پرت و مشکل همخطی چندگانه. (بیور، 1966، ساندرز و آلن، 2002، جونز، 1987)
اواخر دهه ۱۹۶۰: تحلیل ممیزی و معرفی مدل Z-score
در اواخر دهه ۱۹۶۰، تحلیل ممیزی خطی (Linear Discriminant Analysis – LDA) بهعنوان روشی پیشرفتهتر برای طبقهبندی وامگیرندگان مطرح شد. در این میان، مدل Z-score آلتمن (1968) نقطه عطفی در تاریخ رتبهبندی اعتباری بود؛ مدلی که با استفاده از LDA چندین نسبت مالی را در یک تابع خطی ترکیب میکرد تا احتمال ورشکستگی شرکتها را پیشبینی کند. این مدل دقت بالاتری نسبت به روشهای تکمتغیره پیشین، مانند تحلیلهای بیور (1966)، ارائه داد و استفاده از تکنیکهای چندمتغیره را در صنعت مالی رواج بخشید. با وجود مزایای آن، تحلیل ممیزی نیازمند فرض نرمالبودن دادهها و یکسانبودن ساختار کوواریانس بین گروهها بود که در برخی موارد میتوانست اثربخشی آن را کاهش دهد. (آلتمن، 1968، جونز، 1987، کراهنن و وبر، 2001)
دهه ۱۹۸۰: رگرسیون لجستیک
رگرسیون لجستیک در دهه ۱۹۸۰ بهطور گستردهای بهعنوان روشی برای مدلسازی نتایج دوتایی مانند نکول یا عدم نکول پذیرفته شد. این روش، روابط غیرخطی را مدیریت میکرد و برآوردهای احتمالی ارائه میداد، که آن را برای طبقهبندی ریسک اعتباری مفید میساخت. (ساندرز و آلن، ۲۰۰۲) جونز (۱۹۸۷) اثربخشی رگرسیون لجستیک در پیشبینی ورشکستگی را برجسته کرد که نشاندهنده بهبود قابل توجهی در قابلیت اطمینان ارزیابیهای اعتباری بود.
اواخر دهه ۱۹۸۰: سیستمهای خبره
سیستمهای خبره، یکی از اولین کاربردهای هوش مصنوعی در امور مالی، در اواخر دهه ۱۹۸۰ ظهور کردند. این سیستمها فرایندهای تصمیمگیری انسانی را تقلید و از قوانین و روشهای ابتکاری برای ارزیابی ریسک اعتباری استفاده میکردند. اگرچه سیستمهای خبره هم عوامل کیفی و هم کمّی را در نظر میگرفتند، اما توسعه و نگهداری آنها پیچیده بود. (کراهنن و وبر، ۲۰۰۱؛ جونز، ۱۹۸۷) با این حال، آنها زمینه را برای کاربردهای آینده هوش مصنوعی در رتبهبندی اعتباری فراهم کردند. (ساندرز و آلن، ۲۰۰۲)
دهه ۱۹۹۰: درختهای تصمیم
دهه ۱۹۹۰ شاهد معرفی درختهای تصمیم بود که روش بصری و شهودی برای مدلسازی ریسک اعتباری با تقسیم دادهها و بر اساس متغیرهای کلیدی ارائه میداد. درختهای تصمیم در مدیریت روابط غیرخطی و دادههای گمشده موثر بودند (کراهنن و وبر، ۲۰۰۱). با این حال، آنها مستعد بیشبرازش بودند، بهویژه با مجموعه دادههای کوچک یا نویزدار. (جونز، ۱۹۸۷)
اواخر دهه ۱۹۹۰: شبکههای عصبی
شبکههای عصبی در اواخر دهه ۱۹۹۰ محبوب شدند و نقطه عطف مهمی را در رتبهبندی اعتباری نشان دادند. این مدلها الگوهای پیچیده و غیرخطی را در دادهها تشخیص میدادند و دقت پیشبینی را بهبود میبخشیدند. (آلتمن، ۱۹۶۸) اگرچه شبکههای عصبی، انعطافپذیری را در مدیریت مجموعه دادههای بزرگ ارائه میدادند، اما از نظر محاسباتی پرهزینه بودند و اغلب بهدلیل عدم قابلیت تفسیر، بهعنوان «جعبه سیاه» مورد انتقاد قرار میگرفتند. (ساندرز و آلن، ۲۰۰۲؛ جونز، ۱۹۸۷)
| دوره | مدل | ویژگیها و پیشرفتهای کلیدی |
| اوایل دهه 1900 | مدلهای قضاوتی | – وابسته به قضاوت و تجربه شخصی افسران وام
– ارزیابیهای ذهنی با عنوان «پنج C اعتباری» شامل شخصیت، ظرفیت بازپرداخت، سرمایه، وثیقه و شرایط – ناسازگار و دارای تعصب که منجر به رتبهبندیهای اعتباری غیرقابل اعتماد میشد. |
| دهه 1950 | مدلهای امتیازدهی اعتباری | – استفاده از تکنیکهای آماری برای پیشبینی احتمال نکول بر اساس دادههای تاریخی
– فراهم کردن رتبهبندیهای اعتباری عینی و سازگار – کاهش تاثیر تعصب شخصی |
| دهه 1960 | رگرسیون خطی | – استفاده از روابط خطی بین نسبتهای مالی و احتمال نکول
– کمیتسازی تاثیر متغیرهای مالی فردی بر ریسک اعتباری – ارائه چارچوبی روشن و قابل تفسیر |
| دهه 1970 | تحلیل تفکیکی (ممیزی) | – طبقهبندی وامگیرندگان به دستههای ریسک اعتباری بر اساس ویژگیهای مالی
– درنظرگرفتن همزمان چندین متغیر – مدیریت روابط غیرخطی |
| دهه 1980 | رگرسیون لجستیک | – مدیریت موثر خروجیهای دوتایی (نکول/ عدم نکول)
– ارائه برآوردهای احتمالی از ریسک نکول – مدلسازی روابط غیرخطی بین متغیرها |
| اواخر دهه 1980 | سیستمهای خبره | – استفاده از هوش مصنوعی برای تقلید فرایند تصمیمگیری کارشناسان انسانی
– ادغام قوانین برای ارزیابی ریسک اعتباری – کاربرد اولیه AI در امور مالی |
| دهه 1990 | درختهای تصمیمگیری | – استفاده از ساختارهای درختمانند برای تصمیمگیری بر اساس تقسیم ویژگیها
– ارائه نمایه شهودی و بصری – مدیریت روابط غیرخطی و تعاملات بین متغیرها |
| اواخر دهه 1990 | شبکههای عصبی | – شناسایی الگوهای پیچیده در دادهها
– بهبود قابل توجه در دقت پیشبینی – پایهگذاری توسعه مدلهای یادگیری عمیق پیشرفته در دهههای بعدی |

پیشرفت مدلهای رتبهبندی اعتباری
اواخر دهه ۱۹۹۰: شبکههای عصبی
اواخر دهه ۱۹۹۰ دوره تحولآفرینی برای مدلهای رتبهبندی اعتباری با معرفی شبکههای عصبی بود. شبکههای عصبی مدلهای محاسباتی الهامگرفته از ساختار مغز انسان هستند که برای تشخیص الگوهای پیچیده و غیرخطی در دادهها طراحی شدهاند. این مدلها بهبود قابل توجهی در دقت پیشبینی و قابلیت، نسبت به مدلهای آماری سنتی ایجاد کردند.
یک مطالعه قابل توجه توسط آلتمن، مارکو و وارتو (۱۹۹۴) شبکههای عصبی را با تحلیل ممیزی خطی (LDA) برای پیشبینی بحران شرکتها در بازار ایتالیا مقایسه کرد. تحقیق آنها نشان داد که شبکههای عصبی، عملکرد بهتری نسبت به روشهای سنتی LDA داشتند.
در حمایت بیشتر از پتانسیل شبکههای عصبی در ارزیابی ریسک اعتباری، عطیه (۲۰۰۱) یک بررسی جامع در مورد پیشبینی ورشکستگی انجام داد. این مطالعه استحکام و انعطافپذیری شبکههای عصبی در مدیریت مجموعه دادههای بزرگ را نشان داد و اثربخشی آنها را نسبت به روشهای متعارف تقویت کرد.
باسنس و همکاران (۲۰۰۳) الگوریتمهای پیشرفته طبقهبندی برای امتیازدهی اعتباری را مقایسه کردند و نشان دادند که شبکههای عصبی بهطور مداوم عملکرد بهتری نسبت به سایر الگوریتمها داشتند. این یافته شبکههای عصبی را بهعنوان یک تکنیک پیشرو در ارزیابی ریسک اعتباری تثبیت کرد. بعدها، خاشمن (۲۰۱۱) ادغام هوش هیجانی در مدلهای شبکه عصبی را بررسی کرد که منجر به پیشبینیهای حتی دقیقتر با ترکیب عوامل روانشناختی در کنار شاخصهای مالی شد.
در سال ۲۰۰۰، یوباس، کروک و راس شبکههای عصبی را با ادغام تکنیکهای تکاملی مانند الگوریتمهای ژنتیک پیشرفت دادند. این مدل ترکیبی، امکان انتخاب و وزندهی بهینه ویژگیها را فراهم کرد و عملکرد کلی مدل را بهبود بخشید.
بنابراین، اواخر دهه ۱۹۹۰ شبکههای عصبی را بهعنوان ابزاری قدرتمند برای ارزیابی ریسک اعتباری تثبیت کرد که دقت و پیچیدگی در مدیریت روابط غیرخطی و حجم زیادی از دادهها را ارائه میداد.
اوایل دهه ۲۰۰۰: ماشینهای بردار پشتیبان (SVM)
اوایل دهه ۲۰۰۰ ماشینهای بردار پشتیبان (SVM) را بهعنوان روشی قدرتمند دیگر برای ارزیابی ریسک اعتباری معرفی کرد. SVMها دادهها را با یافتن ابرصفحه بهینه که کلاسهای مختلف را جدا میکند، طبقهبندی میکنند و آنها را بهویژه برای امتیازدهی اعتباری، جایی که دادهها اغلب چندبعدی هستند، مفید میسازند.
باسنس و همکاران (۲۰۰۳) SVMها را در مطالعه معیار خود گنجاندند و دریافتند که SVMها عملکردی رقابتی با شبکههای عصبی داشتند و دقت بالایی در پیشبینی ریسک اعتباری ارائه میدادند. آنها چندین مزیت داشتند، از جمله مدیریت موثر مجموعه دادههای نامتوازن (مسئلهای رایج در مدلسازی ریسک اعتباری، جایی که موارد نکول، کمتر از موارد غیرنکول هستند) و تشخیص روابط پیچیده بین متغیرها با استفاده از توابع کرنل.
با وجود اثربخشی آنها، SVMها نیازمند تنظیم دقیق پارامترها بودند و از نظر محاسباتی پرهزینه. با این حال، دقت بالا و قابلیتهای تعمیم آنها، SVMها را به ابزاری ارزشمند در مدلسازی ریسک اعتباری تبدیل کرد.
اواسط دهه ۲۰۰۰: روشهای ترکیبی (مانند جنگلهای تصادفی و تقویت گرادیان)
اواسط دهه ۲۰۰۰ شاهد ظهور روشهای ترکیبی در مدلهای رتبهبندی اعتباری، بهویژه جنگلهای تصادفی و ماشینهای تقویت گرادیان (GBM) بود. این روشها چندین مدل را برای بهبود دقت و استحکام ترکیب میکنند.
جنگلهای تصادفی، که توسط بریمن (۲۰۰۱) معرفی شدند، پیشبینیهای چندین درخت تصمیم را تجمیع میکنند و بیشبرازش را کاهش داده و دقت طبقهبندی را بهبود میبخشند. از سوی دیگر،GBM مدلها را بهصورت متوالی میسازد و خطای مدلهای قبلی را اصلاح میکند تا عملکرد را بهبود بخشد. هر دو روش در مطالعه باسنس و همکاران (۲۰۰۳) بهدلیل دقت پیشبینی برتر، برجسته شدند.
روشهای ترکیبی چندین مزیت داشتند: آنها مقاوم بودند، بیشبرازش را کاهش میدادند و مجموعه دادههای بزرگ را بهطور موثر مدیریت میکردند. توانایی آنها در تجمیع چندین مدل، پیشبینیهای قابل اعتمادتر و دقیقتری ارائه میداد و آنها را به ابزارهای ضروری در ارزیابی ریسک اعتباری در اواسط دهه ۲۰۰۰ تبدیل کرد.
اواخر دهه ۲۰۰۰: شبکههای بیزی
شبکههای بیزی که در اواخر دهه ۲۰۰۰ معرفی شدند، رویکرد احتمالاتی به ارزیابی ریسک اعتباری ارائه دادند و وابستگیها بین متغیرها را از طریق گرافهای جهتدار بدون دور نمایش میدادند. کار پرل (۱۹۸۸) پایه نظری برای شبکههای بیزی را فراهم کرد که امکان ترکیب دانش کارشناسی با روشهای مبتنیبر داده را فراهم میکرد.
شبکههای بیزی بهروزرسانی پویا ارائه میدادند، به این معنی که مدلها میتوانستند با در دسترس قرارگرفتن دادههای جدید بهبود یابند. ساختار گرافیکی واضح آنها امکان تجسم آسان تعاملات پیچیده را فراهم و به تصمیمگیری کمک میکرد.
با وجود مزایای آنها، شبکههای بیزی نیاز به تخصص قابل توجهی برای توسعه داشتند و برای مجموعه دادههای بزرگ از نظر محاسباتی پرهزینه بودند. با این حال، توانایی آنها در مدیریت عدم قطعیت، آنها را به افزودهای ارزشمند در مدلسازی ریسک اعتباری تبدیل کرد.
دهه ۲۰۱۰: یادگیری عمیق
یادگیری عمیق، زیرمجموعهای از شبکههای عصبی با لایههای متعدد در دهه ۲۰۱۰ ظهور کرد و دقت بیسابقهای را به مدلهای ریسک اعتباری آورد. مدلهای یادگیری عمیق در تشخیص الگوهای پیچیده در مجموعه دادههای بزرگ برتری دارند و میتوانند دادههای بدون ساختار مانند متن و تصاویر را مدیریت کنند و بهبود قابل توجهی نسبت به روشهای سنتی ارائه دهند.
هیتون، پولسون و ویته (۲۰۱۷) کاربرد یادگیری عمیق در امور مالی را بررسی کردند و دریافتند که این مدلها عملکرد بهتری نسبت به روشهای آماری سنتی داشتند. تنوع یادگیری عمیق توسط فیشر و کراوس (۲۰۱۸) که از شبکههای حافظه کوتاهمدت طولانی (LSTM) برای تحلیل دادههای بازار مالی استفاده کردند، بیشتر تاکید شد. LSTMها بهویژه در تشخیص وابستگیهای زمانی، که در ارزیابی ریسک اعتباری ضروریست، موثر هستند.
نیاکی و نونتالیراک (۲۰۱۶) نشان دادند که شبکههای عصبی یادگیری عمیق میتوانند نرخهای نکول را دقیقتر از روشهای سنتی پیشبینی کنند، در حالی که سیریگنانو و کونت (۲۰۱۹) اثربخشی آنها را در تشخیص پویاییهای پیچیده بازار نشان دادند.
مدلهای یادگیری عمیق مزایای کلیدی مانند استخراج خودکار ویژگیها، انعطافپذیری در مدیریت انواع مختلف دادهها و توانایی مدلسازی روابط غیرخطی را ارائه میدادند. با این حال، پیچیدگی و نیازهای محاسباتی آنها چالشهایی را ایجاد میکرد، اما بهبود در دقت پیشبینی، یادگیری عمیق را به ابزاری ضروری در مدلهای مدرن ریسک اعتباری تبدیل کرد.
اواسط دهه ۲۰۱۰:XGBoost و ماشینهای تقویت گرادیان (GBM)
XGBoost که در اواسط دهه ۲۰۱۰ معرفی شد، پیادهسازی کارآمد و مقیاسپذیری از تقویت گرادیان ارائه داد. سرعت، دقت بالا و توانایی آن در مدیریت مجموعه دادههای بزرگ، آن را به روشی ترجیحی در مدلسازی ریسک اعتباری تبدیل کرد. (باسنس و همکاران، ۲۰۰۳)
ماشینهای تقویت گرادیان (GBM) در طول دهه ۲۰۱۰ همچنان یک انتخاب برتر برای ارزیابی ریسک اعتباری باقی ماندند، بهویژه بهدلیل رویکرد تکراری آنها در اصلاح خطاهای قبلی. عملکرد XGBoost با کارایی محاسباتی آن مشخص شد و تکنیکهای تنظیم آن به جلوگیری از بیشبرازش کمک کرد. علیرغم اثربخشی آنها،XGBoost و GBM نیاز به تنظیم دقیق پارامترها داشتند و میتوانستند برای مبتدیان پیچیده باشند. با این حال، دقت پیشبینی و استحکام، آنها را در رتبهبندی اعتباری بسیار ارزشمند ساخت.
اواخر دهه ۲۰۱۰ :LightGBM و CatBoost
اواخر دهه ۲۰۱۰ شاهد نوآوریهای بیشتر در روشهای ترکیبی با توسعه LightGBM و CatBoost بود. الگوریتمهای یادگیری مبتنیبر درخت LightGBM و سرعت آموزش بالا، آن را در مدیریت مجموعه دادههای بزرگ، کارآمد ساخت. توانایی آن در مدیریت خودکار و کارآمد ویژگیهای دستهای بهویژه در مدلسازی ریسک اعتباری مزیت داشت. (باسنس و همکاران، ۲۰۰۳)
CatBoost در مدیریت دادههای دستهای تخصص داشت و نوآوریهایی ارائه میداد که بیشبرازش را کاهش داده و دقت مدل را بهبود میبخشید. هر دو الگوریتم به انتخابهای ترجیحی برای موسسات مالی تبدیل شدند، زیرا تعادلی بین دقت، سرعت و کارایی ارائه میدادند.
دهه ۲۰۲۰: هوش مصنوعی قابل توضیح (XAI)
با پیچیدهترشدن مدلهای ریسک اعتباری، تقاضا برای قابلیت توضیح افزایش یافت. دهه ۲۰۲۰ هوش مصنوعی قابل توضیح (XAI) ظهور کرد که هدف آن، ارائه شفافیت و قابلیت تفسیر به مدلهای ریسک اعتباری بود. مدلهای XAI با ارائه توضیحات روشن برای پیشبینیهای خود، عدالت و پاسخگویی را تضمین میکنند که برای انطباق با مقررات و اعتماد مشتری بسیار مهم است. (باسنس و همکاران، ۲۰۰۳)
اگرچه توسعه مدلهای XAI پیچیدهتر است، شفافیت آنها در صنعت مالی، جایی که تصمیمگیری باید شفاف و بدون تعصب باشد، بسیار ارزشمند است.
جدول پیشرفت مدلهای رتبهبندی اعتباری
| دوره | مدل | ویژگیها و پیشرفتهای کلیدی |
| اواخر دهه 1990 | شبکههای عصبی | – تقلید از ساختار نورونهای مغز انسان
– شناسایی الگوهای پیچیده و غیرخطی – بهبود قابلیتهای پیشبینی نسبت به مدلهای آماری سنتی |
| اوایل دهه 2000 | ماشینهای بردار پشتیبان (SVM) | – طبقهبندی دادهها با یافتن ابرصفحه بهینه
– استحکام در مدیریت فضاها با ابعاد بالا – موثر در مدیریت مجموعه دادههای نامتوازن |
| اواسط دهه 2000 | روشهای مجموعهای (جنگل تصادفی، GBM) | – ترکیب چندین مدل برای بهبود عملکرد پیشبینی
– جنگلهای تصادفی با استفاده از چندین درخت تصمیمگیری بیشبرازش را کاهش میدهند. – GBM مدلها را بهصورت متوالی میسازد و خطاهای قبلی را تصحیح میکند. |
| اواخر دهه 2000 | شبکههای بیزی | – رویکرد احتمالاتی با استفاده از گراف جهتدار بدون دور
– ترکیب روشهای مبتنیبر داده و متخصص – بهروزرسانی باورها بر اساس اطلاعات جدید – چارچوب گرافیکی واضح برای درک روابط بین متغیرها |
| دهه 2010 | یادگیری عمیق | – شبکههای عصبی با چندین لایه
– شناسایی الگوهای پیچیده در مجموعههای بزرگ داده – مدیریت دادههای غیرساختاری مانند متن و تصاویر |
| دهه 2010 | ماشینهای گرادیان بوستینگ (GBM) | – تمرکز بر تقویت یادگیرندههای ضعیف
– رویکرد تکراری برای دقت بالا – انعطافپذیری در مدیریت انواع دادهها و مشکلات پیشبینی |
| اواسط دهه 2010 | XGBoost | – پیادهسازی کارآمد و مقیاسپذیر گرادیان بوستینگ
– مدیریت مجموعههای بزرگ داده – دقت بالا با هزینه محاسباتی نسبتاً کم |
| اواخر دهه 2010 | LightGBM | – بهبود کارایی گرادیان بوستینگ با استفاده از الگوریتمهای یادگیری مبتنیبر درخت
– سرعت بالای آموزش و پیشبینی – مدیریت خودکار ویژگیهای دستهای |
| اواخر دهه 2010 | CatBoost | – تخصص در مدیریت خودکار ویژگیهای دستهای
– کاهش نیاز به پیشپردازش گسترده دادهها – استحکام در برابر بیشبرازش |
| دهه 2020 | مدلهای هوش مصنوعی قابل توضیح (XAI) | – تمرکز بر شفافیت و تفسیرپذیری تصمیمات هوش مصنوعی
– ارائه توضیحات واضح برای پیشبینیها – اطمینان از تصمیمات اعتباری منصفانه و پاسخگو |
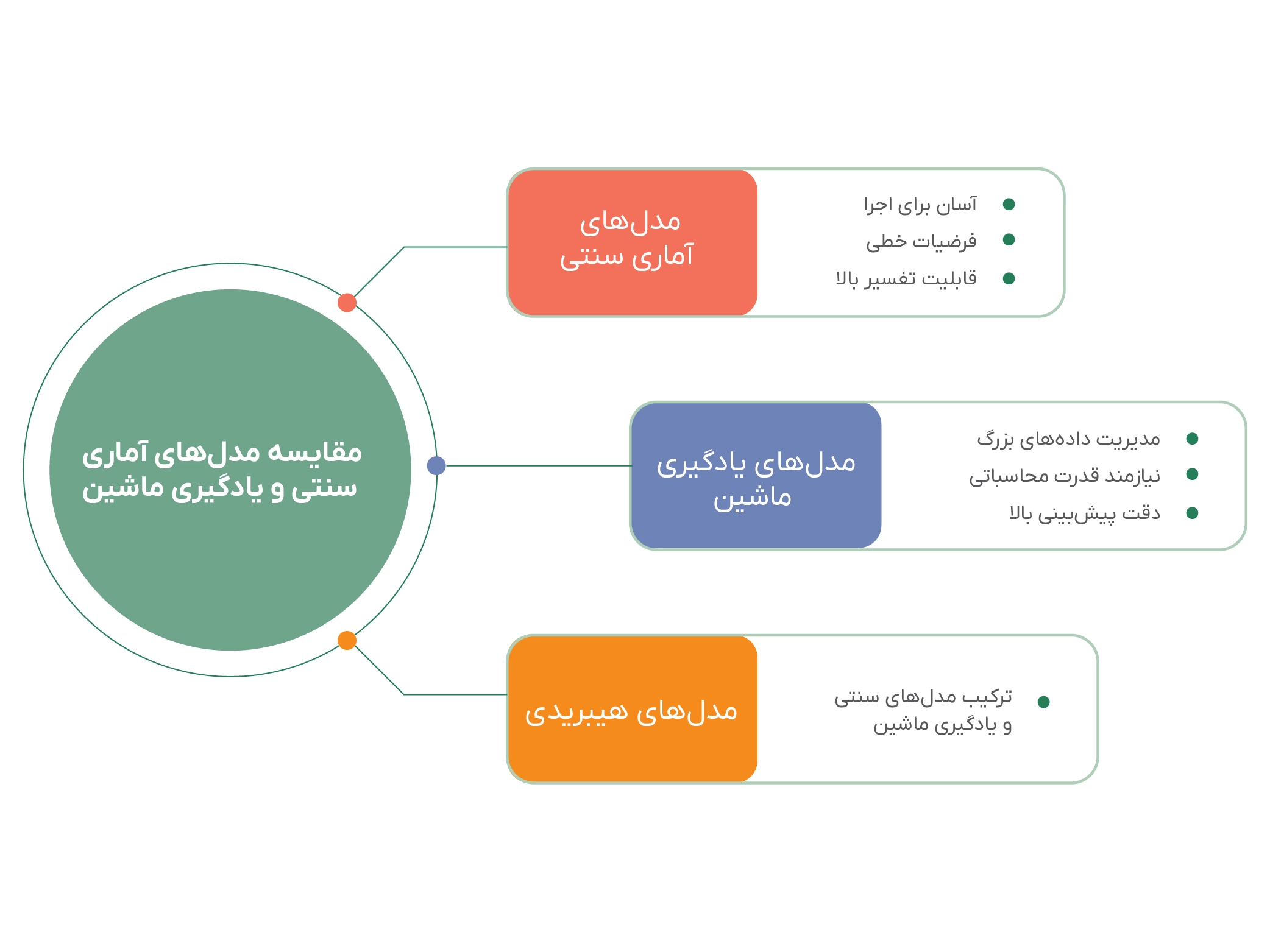
تحلیل مقایسهای مدلهای امتیازدهی اعتباری
1. مدلهای آماری سنتی
مدلهای آماری کلاسیک مانند رگرسیون خطی، رگرسیون لجستیک و تحلیل ممیزی، برای سالها زیربنای اصلی سیستمهای امتیازدهی اعتباری بودهاند. این مدلها بهدلیل سادگی، سهولت پیادهسازی و قابلیت تفسیر بالا، بهویژه در محیطهای نظارتی، همواره مورد توجه قرار داشتهاند.
رگرسیون لجستیک، بهعنوان یکی از رایجترین ابزارها برای مدلسازی متغیرهای دودویی، امکان تخمین احتمال نکول را فراهم میسازد و از این رو در بسیاری از سیستمهای اعتبارسنجی به کار گرفته میشود. (توماس، ادلمن و کروک، ۲۰۰۲) تحلیل ممیزی نیز که برای طبقهبندی دادهها موثر است، به فروضی نظیر نرمالبودن چندمتغیره و تساوی ماتریسهای کوواریانس میان گروهها وابسته بوده و در صورت نقض این فروض، دقت آن کاهش مییابد. (توماس و همکاران، ۲۰۰۲)
2. مدلهای یادگیری ماشین
با گسترش دادههای کلان و افزایش توان پردازشی، مدلهای پیشرفتهتری تحت عنوان یادگیری ماشین وارد حوزه امتیازدهی اعتباری شدهاند. این مدلها شامل درختهای تصمیم، ماشینهای بردار پشتیبان (SVM)، شبکههای عصبی و روشهای ترکیبی نظیر جنگلهای تصادفی و گرادیان بوستینگ (GBM) هستند.
مزیت اصلی این مدلها، توانایی در شناسایی روابط غیرخطی، تعاملات پیچیده بین متغیرها و قابلیت پردازش دادههای بزرگ است. مطالعات تجربی نشان دادهاند که بسیاری از این مدلها، بهویژه روشهای ترکیبی، دقت بالاتری در پیشبینی ریسک نکول نسبت به مدلهای سنتی دارند. (بایسنز و همکاران، ۲۰۰۳؛ لسمان و همکاران، ۲۰۱۵) با این حال، چالشهایی مانند نیاز به منابع محاسباتی قابل توجه، پیادهسازی پیچیده و تفسیرپذیری محدود، مانع استفاده گسترده آنها در برخی کاربردهای نظارتی شده است.
3. تحلیل مقایسهای میان مدلهای سنتی و یادگیری ماشین
در این بخش، عملکرد دو دسته مدل معرفیشده با استناد به مطالعات تجربی، معیارهای ارزیابی کلیدی و ملاحظات کاربردی، مورد بررسی و مقایسه قرار میگیرد:
-
شواهد تجربی
مطالعات تطبیقی متعددی به مقایسه مستقیم بین مدلهای سنتی و مدلهای یادگیری ماشین پرداختهاند. برای مثال، یه و لین (۲۰۰۹) در مطالعهای روی مشتریان کارت اعتباری نشان دادند که شبکههای عصبی و ماشینهای بردار پشتیبان (SVM) عملکرد بهتری نسبت به درختهای تصمیم دارند. با این حال، در حوزههایی مانند اعتبارسنجی در موسسات مالی که شفافیت و قابلیت تفسیر خروجیها از اهمیت بالایی برخوردار است، مدلهای سنتی همچنان گزینهای قابل اتکاست. (عبده و پوینتون، ۲۰۱۱)
از سوی دیگر، مطالعاتی مانند تحقیق بایسنز و همکاران (۲۰۰۳) و همچنین لسمان و همکاران (۲۰۱۵) نشان میدهند که روشهای مجموعهای مانند جنگل تصادفی و GBM ضمن دستیابی به دقت بالا، در برابر بیشبرازش نیز مقاومتر عمل میکنند.
-
معیارهای ارزیابی عملکرد
مقایسه عملکرد مدلهای امتیازدهی اعتباری بر پایه مجموعهای از معیارهای کلیدی صورت میگیرد؛ از جمله:
- دقت پیشبینی (Accuracy)
- تفسیرپذیری (Interpretability)
- کارایی محاسباتی (Computational Efficiency)
- استحکام یا تعمیمپذیری (Robustness)
مدلهای یادگیری ماشین، بهویژه مدلهای ترکیبی، اغلب در شاخص دقت پیشبینی، عملکرد بهتری دارند. در مقابل، مدلهایی نظیر رگرسیون لجستیک از تفسیرپذیری بالاتری برخوردار بوده و در محیطهایی با الزامات نظارتی، مزیت مهمی به شمار میآیند. همچنین، مدلهای ترکیبی بهدلیل استفاده از چند الگوریتم بهصورت همزمان، اغلب در برابر بیشبرازش مقاومتر هستند و عملکرد پایدارتری از خود نشان میدهند. (یه و لین، ۲۰۰۹)
- ملاحظات کاربردی در انتخاب مدل
انتخاب مدل مناسب برای امتیازدهی اعتباری بستگی زیادی به ماهیت دادهها، الزامات قانونی، منابع در دسترس و اهداف عملیاتی دارد. برای مثال:
- در کاربردهایی که توضیح تصمیمهای مدل برای ذینفعان یا نهادهای نظارتی الزامی است، مدلهای آماری سنتی معمولا ترجیح داده میشوند.
- در مقابل، برای کاربردهایی مانند فیلتر اولیه مشتریان پرریسک، که دقت بالای پیشبینی، اهمیت بیشتری دارد، استفاده از مدلهای یادگیری ماشین یا مدلهای ترکیبی میتواند مناسبتر باشد.
در سالهای اخیر، استفاده از مدلهای هیبریدی که تلاش میکنند دقت مدلهای یادگیری ماشین را با تفسیرپذیری مدلهای سنتی تلفیق کنند، رو به افزایش بوده است. (لسمان و همکاران، ۲۰۱۵)
| ویژگی | مدلهای آماری سنتی | مدلهای یادگیری ماشین |
| مدلهای شاخص | رگرسیون خطی، رگرسیون لجستیک، تحلیل ممیزی | درختهای تصمیم، ماشین بردار پشتیبان (SVM)، شبکههای عصبی، جنگل تصادفی، گرادیان بوستینگ (GBM) |
| نقاط قوت | سادگی، قابلیت تفسیر بالا، پیادهسازی آسان، مناسب برای محیطهای نظارتی | دقت پیشبینی بالا، توانایی شناسایی روابط پیچیده، مدیریت دادههای حجیم، عملکرد خوب در دادههای غیرخطی |
| نقاط ضعف | فرض روابط خطی، وابستگی به فروض آماری (نرمالبودن، کوواریانس برابر)، ضعف در الگوهای غیرخطی | پیچیدگی پیادهسازی، نیاز به منابع محاسباتی بالا، تفسیرپذیری محدود، دشواری در کاربرد نظارتی |
| دقت پیشبینی | قابل قبول در بسیاری از کاربردها، اما محدود در مدلسازی تعاملات پیچیده | معمولاً بالاتر از مدلهای سنتی، بهویژه در روشهای ترکیبی |
| تفسیرپذیری | بسیار بالا؛ امکان تحلیل وزنی متغیرها و ارائه استدلال شفاف | پایینتر؛ بهویژه در مدلهای پیچیده مانند شبکههای عصبی و GBM |
| استحکام (Robustness) | متوسط؛ در صورت نقض فروض آماری دچار افت عملکرد میشود | بالا؛ روشهای ترکیبی در برابر بیشبرازش مقاوم هستند |
| کارایی محاسباتی | بالا؛ نیاز به منابع کم و سرعت اجرا مناسب | پایینتر؛ به منابع و زمان پردازش بیشتری نیاز دارد، بهویژه در یادگیری عمیق |
| مطالعات تجربی شاخص | توماس و همکاران (۲۰۰۲): تأکید بر تفسیرپذیری و سادگی مدلهای سنتی | بایسنز و همکاران (۲۰۰۳)، لسمان و همکاران (۲۰۱۵): برتری در دقت و استحکام مدلهای ترکیبی یادگیری ماشین |
| ملاحظات عملی | مناسب برای محیطهای قانونمحور و زمانی که شفافیت تصمیمگیری حیاتی است | مناسب برای کاربردهای پرریسک یا نیازمند دقت بالا، در صورت وجود منابع و توانایی فنی |
| پیشنهاد کاربردی | استفاده در مواردی که تفسیرپذیری، شفافیت، و پیادهسازی سریع مهم است | استفاده در مواردی که دقت بالا و قدرت پیشبینی اولویت دارد؛ مدلهای هیبریدی برای تعادل بین دقت و شفافیت مناسباند |
چالشها و جهتگیریهای آینده در مدلهای رتبهبندی اعتباری
چالشها در مدلهای رتبهبندی اعتباری
چندین چالش مهم بر اثربخشی مدلهای رتبهبندی اعتباری تاثیر میگذارد، از جمله کیفیت دادهها، قابلیت تفسیر مدل، انطباق با مقررات و ماهیت در حال تحول بازارهای مالی.
1. کیفیت و دردسترسبودن دادهها
اطمینان از دادههای با کیفیت بالا و جامع برای مدلهای اعتباری بهدلیل مسائلی مانند سوابق ناقص و نگرانیهای مربوط به حریم خصوصی دادهها چالشبرانگیز است. (هند و هنلی، ۱۹۹۷) ماهیت پویای بازارهای مالی همچنین به این معنی است که دادههای تاریخی بهسرعت منسوخ میشوند و نیاز به بهروزرسانیهای مداوم دارند. (میز، ۲۰۰۱)
2. قابلیت تفسیر مدل
مدلهای یادگیری ماشین، اگرچه دقیق هستند، اغلب بهدلیل پیچیدگی و عدم شفافیت، مورد انتقاد قرار میگیرند. این ماهیت «جعبه سیاه» در صنعت مالی، جایی که الزامات نظارتی، خواستار تصمیمات قابل توضیح هستند، مشکلساز است. (کاروانا و نیکولسکو- میزیل، ۲۰۰۶)
3. انطباق با مقررات
موسسات مالی باید از مقرراتی مانند قانون فرصت برابر اعتباری (ECOA) پیروی کنند تا از شیوههای غیر تبعیضآمیز در وامدهی اطمینان حاصل کنند. رعایت این مقررات هنگام استفاده از مدلهای پیچیده یادگیری ماشین میتواند دشوار باشد. (میز، ۲۰۰۱)
4. بازارهای مالی در حال تحول
تغییرات سریع در شرایط اقتصادی و روندهای بازار، نظارت مداوم بر مدل، اعتبارسنجی و واسنجی مجدد را برای حفظ دقت پیشبینی ضروری میسازد. (توماس، ۲۰۰۰)
جهتگیریهای آینده در مدلهای رتبهبندی اعتباری
با وجود این چالشها، پیشرفتهای امیدوارکنندهای در این زمینه وجود دارد، از جمله مدلهای ترکیبی، ادغام دادههای جایگزین، هوش مصنوعی قابل توضیح و تکنیکهای پیشرفته.
1. مدلهای ترکیبی
مدلهای ترکیبی، دقت یادگیری ماشین را با قابلیت تفسیر روشهای سنتی ترکیب میکنند و رویکردی متعادل ارائه میدهند. (تسای و چن، ۲۰۱۰)
2. منابع داده جایگزین
ادغام دادههای غیرسنتی مانند فعالیت رسانههای اجتماعی و پرداختهای خدمات عمومی میتواند قدرت پیشبینی مدلهای اعتباری را افزایش دهد، بهویژه برای افرادی با سوابق اعتباری محدود. (هند و هنلی، ۱۹۹۷)
3. هوش مصنوعی قابل توضیح
تکنیکهایی مانند تقطیر مدل و LIME در حال توسعه هستند تا قابلیت تفسیر مدل را بهبود بخشند و انطباق با مقررات و اعتماد ذینفعان را تضمین کنند. (کاروانا و نیکولسکو- میزیل، ۲۰۰۶)
4. تکنیکهای پیشرفته
یادگیری انتقالی و یادگیری تقویتی، روشهای جدیدی برای بهبود انطباقپذیری و عملکرد مدلهای رتبهبندی اعتباری در شرایط متغیر بازار ارائه میدهند. (تسای و چن، ۲۰۱۰)
5. فناوری بلاکچین
بلاکچین میتواند شفافیت و یکپارچگی دادهها را بهبود بخشد و به نگرانیهای مربوط به کیفیت و حریم خصوصی دادهها رسیدگی کند. (هند و هنلی، ۱۹۹۷)
6. امتیازدهی اعتباری بلادرنگ و هوش مصنوعی اخلاقی
پیشرفتها در امتیازدهی اعتباری بلادرنگ و تکنیکهایی برای اطمینان از عدالت در مدلهای مبتنیبر هوش مصنوعی نیز آینده سیستمهای رتبهبندی اعتباری را شکل میدهند (توماس، ۲۰۰۰؛ میز، ۲۰۰۱).
تکامل مداوم مدلهای رتبهبندی اعتباری، ماهیت پویای ارزیابی ریسک مالی را برجسته میکند. همانطور که فناوری پیشرفت میکند، روشهایی که ما برای ارزیابی ریسک اعتباری استفاده میکنیم نیز باید تکامل یابند تا اطمینان حاصل شود که در یک چشمانداز مالی همواره در حال تغییر، موثر، شفاف و عادلانه باقی میمانند.
منابع
Abdou, H., & Pointon, J. (2011). Credit scoring, statistical techniques, and evaluation criteria: A review of the literature. Intelligent Systems in Accounting, Finance and Management, 18(2-3), 59-88.
Altman, E. I. (1968). Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The Journal of Finance, 23(4), 589-609.
Altman, E. I., Marco, G., & Varetto, F. (1994). Corporate distress diagnosis: Comparisons using linear discriminant analysis and neural networks (the Italian experience). Journal of Banking & Finance, 18(3), 505-529.
Altman, E. I., & Rijken, H. A. (2004). How rating agencies achieve rating stability. Journal of Banking & Finance, 28(11), 2679-2714.
Altman, E. I., & Saunders, A. (1998). Credit risk measurement: Developments over the last 20 years. Journal of Banking & Finance, 21(11-12), 1721-1742.
Atiya, A. F. (2001). Bankruptcy prediction for credit risk using neural networks: A survey and new results. IEEE Transactions on Neural Networks, 12(4), 929-935.
Baesens, B., Van Gestel, T., Viaene, S., Stepanova, M., Suykens, J., & Vanthienen, J. (2003). Benchmarking state-of-the-art classification algorithms for credit scoring. Journal of the Operational Research Society, 54(6), 627-635.
Basel Committee on Banking Supervision. (2000). Principles for the management of credit risk. Bank for International Settlements.
Beaver, W. H. (1966). Financial ratios as predictors of failure. Journal of Accounting Research, 4, 71-111.
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32.
Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and regression trees. CRC Press.
Cantor, R., & Packer, F. (1996). Determinants and impacts of sovereign credit ratings. Economic Policy Review, 2(2), 37-53.
Caruana, R., & Niculescu-Mizil, A. (2006). An empirical comparison of supervised learning algorithms. Proceedings of the 23rd International Conference on Machine Learning, 161-168.
Chen, S., & Dhillon, I. S. (2019). Deep learning with label proportions applied to credit rating. IEEE Transactions on Knowledge and Data Engineering, 31(10), 1885-1898.
Durand, D. (1941). Risk elements in consumer instalment financing. National Bureau of Economic Research.
Fischer, T., & Krauss, C. (2018). Deep learning with long short-term memory networks for financial market predictions. European Journal of Operational Research, 270(2), 654-669.
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2), 179-188.
Fitch Ratings. (2021). The Importance of Credit Ratings in Financial Markets.
Green, W. H. (1978). On the asymptotic covariance matrix of the QML estimator for the linear regression model under misspecification. Journal of Econometrics, 10(3), 361-367.
Hand, D. J., & Henley, W. E. (1997). Statistical classification methods in consumer credit scoring: A review. Journal of the Royal Statistical Society: Series A (Statistics in Society) , 160(3), 523-541.
Heaton, J. B., Polson, N. G., & Witte, J. H. (2017). Deep learning in finance. Annual Review of Financial Economics, 9, 201-222.
Jones, F. L. (1987). Current techniques in bankruptcy prediction. Journal of Accounting Literature, 6, 131-164.
Kaplan, R. S., & Urwitz, G. (1979). Statistical models of bond ratings: A methodological inquiry. Journal of Business, 52(2), 231-261.
Khashman, A. (2011). Credit risk evaluation using neural networks: Emotional versus conventional models. Applied Soft Computing, 11(8), 5477-5484.
Krahnen, J. P., & Weber, M. (2001). Generally accepted rating principles: A primer. Journal of Banking & Finance, 25(1), 3-26.
Lessmann, S., Baesens, B., Seow, H. V., & Thomas, L. C. (2015). Benchmarking state-of-the-art machine learning techniques for credit scoring. Journal of the Operational Research Society, 66(6), 743-751.
Mays, E. (Ed.). (2001). Handbook of credit scoring. Chicago: Glenlake Publishing Company, Ltd.
Merton, R. C. (1974). On the pricing of corporate debt: The risk structure of interest rates. The Journal of Finance, 29(2), 449-470.
Myers, S. C., & Majluf, N. S. (1984). Corporate financing and investment decisions when firms have information that investors do not have. Journal of Financial Economics, 13(2), 187-221.
Quinlan, J. R. (1986). Induction of decision trees. Machine Learning, 1(1), 81-106.
Saunders, A., & Allen, L. (2002). Credit risk measurement: New approaches to value at risk and other paradigms. Wiley.
Sirignano, J., & Cont, R. (2019). Universal features of price formation in financial markets: Perspectives from deep learning. Quantitative Finance, 19(1), 9-27.
Steinberg, D., & Colla, P. (1995). CART: Tree-structured non-parametric data analysis. Salford Systems.
Thomas, L. C. (2000). A survey of credit and behavioural scoring: Forecasting financial risk of lending to consumers. International Journal of Forecasting, 16(2), 149-172.
Thomas, L. C., Edelman, D. B., & Crook, J. N. (2002). Readings in credit scoring: Foundations, developments, and aims. Oxford University Press.
Tsai, C. F., & Chen, M. L. (2010). Credit rating by hybrid machine learning techniques. Applied Soft Computing, 10(2), 374-380.
Tufféry, S. (2011). Data mining and statistics for decision making. Wiley.
Yeh, I. C., & Lien, C. H. (2009). The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients. Expert Systems with Applications, 36(2), 2473-2480.
Yobas, M. B., Crook, J. N., & Ross, P. (2000). Credit scoring using neural and evolutionary techniques. IMA Journal of Management Mathematics, 11(2), 111-125.




